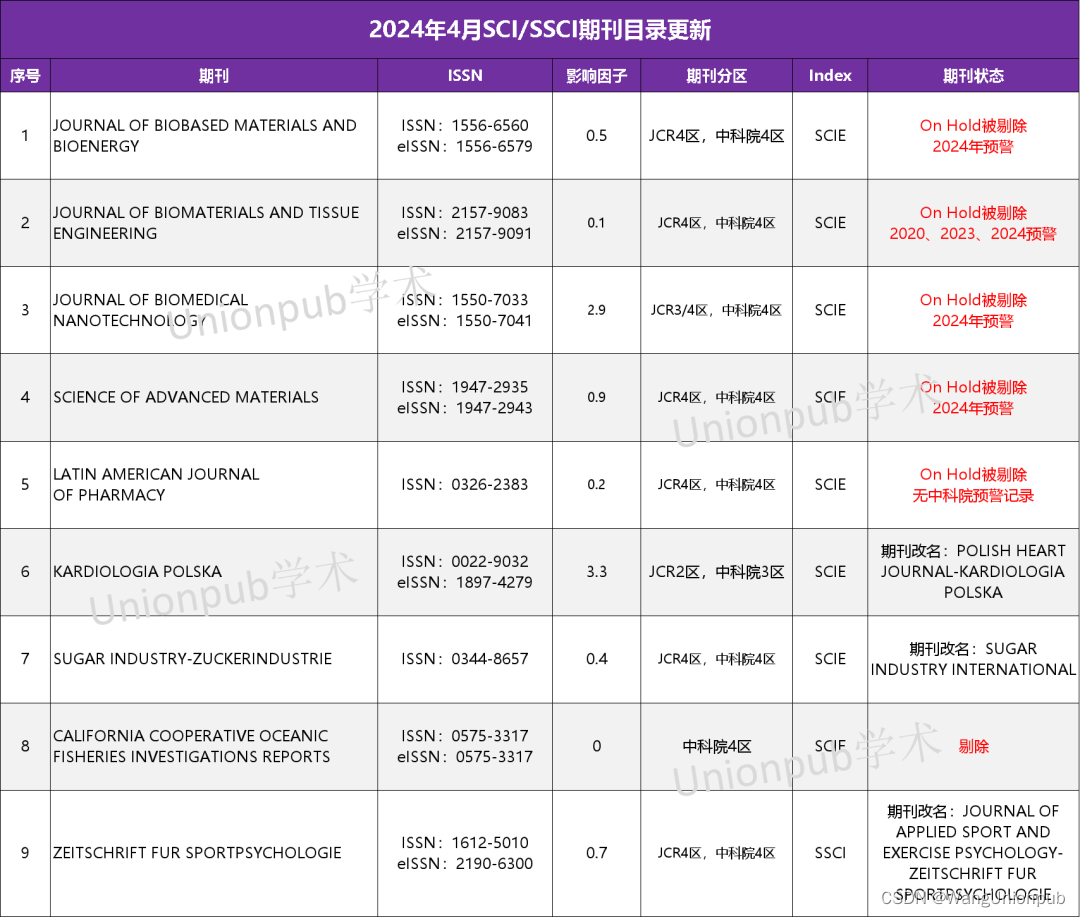
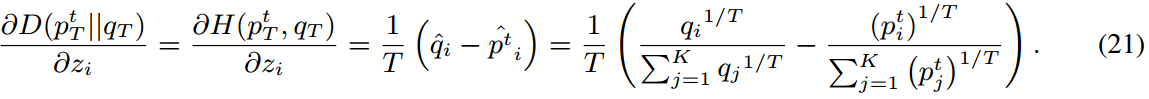在上一篇博客中,我们学习了多重查询(Multi Query)技术,Multi Query的基本思想是当用户输入查询语句(自然语言)时,我们让大模型(LLM)基于用户的问题再生成多个查询语句,这些生成的查询语句是对用户查询语句的补充,它们是从不同的视角来补充用户的查询语句,然后每条查询语句都会从向量数据库中检索到一批相关文档,最后所有的相关文档都会被喂给LLM,这样LLM就会生成比较完整和全面的答案。这样就可以避免因为查询语句的差异而导致结果不正确。如下图所示:
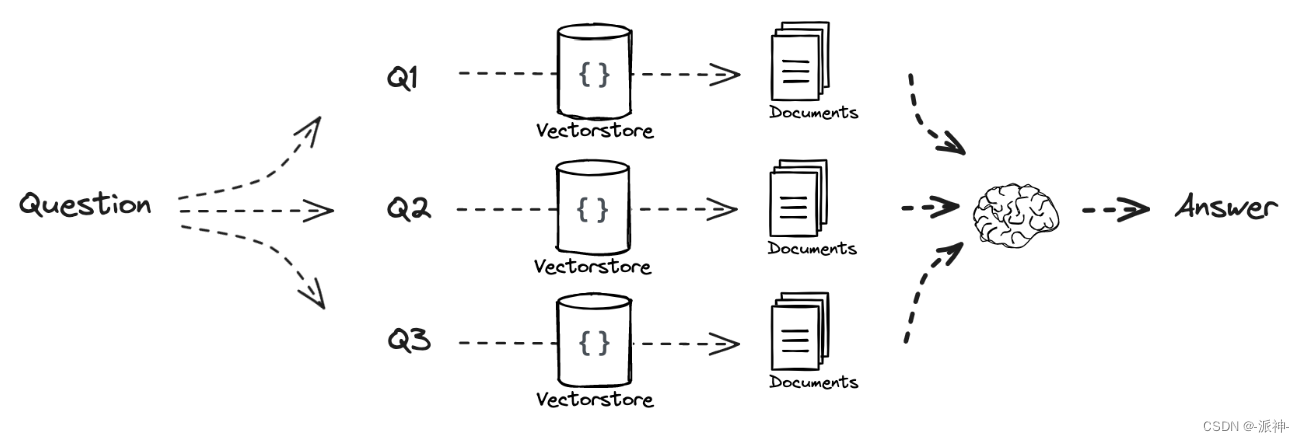
今天我们来介绍RAG 融合(rag fusion),它的主要思想是在Multi Query的基础上,对其检索结果进行重新排序(即reranking)后输出Top K个最相关文档,最后将这top k个文档喂给LLM并生成最终的答案(answer)。如下图所示:
一、环境配置
我们需要安装如下python包:
pip install langchain langchain_openai langchain_pinecone langchainhub接下来我们需要导入所需要设置本次实验所需要用的几个api key:OPENAI_API_KEY,PINECONE_API_KEY,LANGCHAIN_API_KEY,这里需要说明的是本次实验会使用到openai的gpt-3.5-turbo模型,Pinecone向量数据库(PINECONE_API_KEY), LangSmith(LANGCHAIN_API_KEY).
pinecone云向量数据库是一个在线的云端向量数据库,我们需要去其官网申请api key, LangSmith 是用来跟踪和分析langchain组件在执行过程中产生的中间结果,这对我们理解langchain组件的功能和作用有很大的帮助,因此我们也需要去langchain官网申请一个api key。
import os
from dotenv import load_dotenv, find_dotenv
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
#导入项目中需要用到的各种的api_key
_ = load_dotenv(find_dotenv()) # read local .env file
os.environ['OPENAI_API_KEY']=os.environ['OPENAI_API_KEY']
os.environ['PINECONE_API_KEY']=os.environ['PINECONE_API_KEY']
# 导入langsmith所需要的api key,用于跟踪中间结果
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
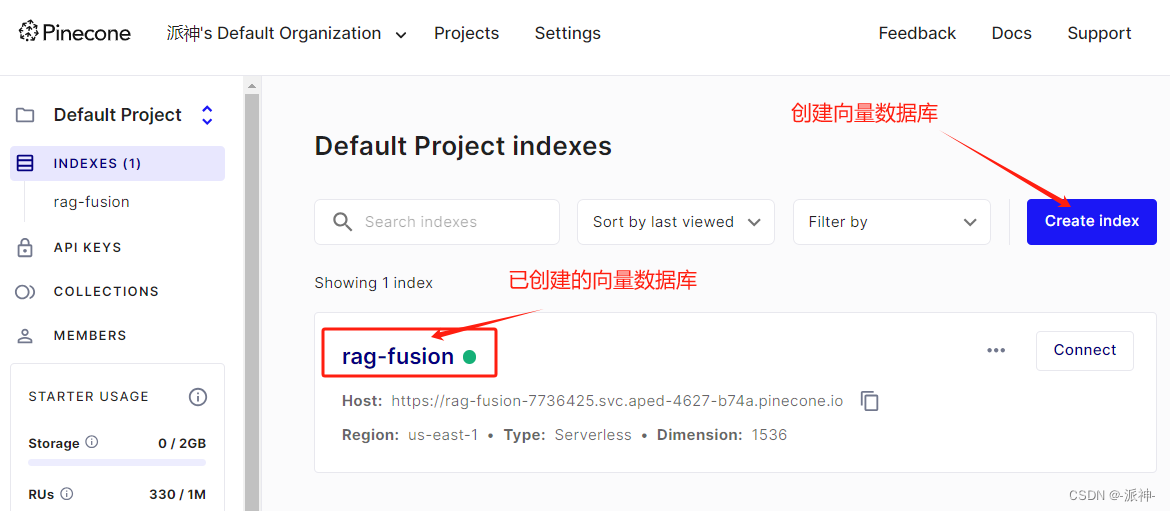
os.environ['LANGCHAIN_API_KEY'] = os.environ['LANGCHAIN_API_KEY']接下来我们还需要去pinecone官网创建一个向量数据库,这里我们创建了一个名为:rag-fusion的空向量数据库,后面需要被检索的文档向量会被自动上传到该向量数据库中:
下面我们来创建一组本次实验所需的测试文档集合,一共10个文档,每个文档为一句中文的句子,每个文档的内容在语义上基本都和气候变化相关:
all_documents={
"doc1": "气候变化和经济影响。",
"doc2": "气候变化引起的公共卫生问题。",
"doc3": "气候变化:社会视角。",
"doc4": "气候变化的技术解决方案。",
"doc5": "应对气候变化需要改变政策。",
"doc6": "气候变化及其对生物多样性的影响。",
"doc7": "气候变化:科学和模型。",
"doc8": "全球变暖:气候变化的一个子集。",
"doc9": "气候变化如何影响日常天气。",
"doc10": "气候变化行动主义的历史。",
}接下来我们需要创建pinecone的向量数据库,在创建向量数据库时,我们指定使用openai的embedding模型,以及向量数据库名(rag-fusion), 需要说明的是这里我们使用的是from_texts的方法来创建向量数据库,它的作用是往云端的向量数据库"rag-fusion"中上传文档向量,这样云端的"rag-fusion"向量库就不再是一个空的数据库了:
vectorstore = PineconeVectorStore.from_texts(
list(all_documents.values()), OpenAIEmbeddings(), index_name="rag-fusion"
)二、定义查询生成器(Multi Quer)
我们现在将定义一个chain来生成多重查询语句,如果对多重查询还不熟悉的朋友,可以查看我之前写的这篇博客。这里我们会首先创建生成多重查询的prompt, 我们可以从langchain官网拉取预先定义好的prompt, 也可以手动定义prompt:
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain import hub
prompt = hub.pull("langchain-ai/rag-fusion-query-generation")
prompt 
同样我们也可以手动创建多重查询的prompt:
# prompt = ChatPromptTemplate.from_messages([
# ("system", "You are a helpful assistant that generates multiple search queries based on a single input query."),
# ("user", "Generate multiple search queries related to: {original_query}"),
# ("user", "OUTPUT (4 queries):")
# ])接下来我们来创建一个生成多重查询的chain, 该chain会根据用户的query生成4个多角度的query, 这些多角度的query是对用户原始query的补充。
generate_queries = (
prompt | ChatOpenAI(temperature=0) | StrOutputParser() | (lambda x: x.split("\n"))
)
original_query = "气候变化的影响"
queries = generate_queries.invoke({"original_query": original_query})
queries ![]()
这里我们看到用户的原始问题是: 气候变化的影响,generate_queries根据用户的问题生成了4个多角度的问题来对用户问题进行补充。
三、定义完整链
我们现在可以将它们放在一起并定义完整的用于检索的chain。该chain的作用是:
1. 生成一组查询(queries)
2. 在检索器中对每个query进行检索
3. 使用倒排序排名融合方法将所有结果连接在一起
请注意,该chain不执行最后的生成步骤(不会将top k的检索结果喂给LLM)
original_query = "气候变化的影响"接下来我们来创建一个向量库的实例并通过该向量库实例来创建一个检索器。
vectorstore = PineconeVectorStore.from_existing_index("rag-fusion", OpenAIEmbeddings())
retriever = vectorstore.as_retriever()下面我们需要定义倒排序排名算法(Reciprocal Rank Fusion (RRF)),该算法来源于这篇论文:Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods,下面是该算法在论文中的定义:

RRF 是与滑铁卢大学 (CAN) 和 Google 合作开发的,用其作者的话说,“比任何单独的系统产生更好的结果,比标准的”重新排名方法更好。我们简单解释一下该算法的原理,在RRF算法中,D表示相关文档的全集,k是固定常数60,r(d)表示当前文档d在其子集中的位置。该算法会对文档全集D进行二重遍历,外层遍历文档全集D, 内层遍历文档子集,在做内层变量的时候我们会累计当前文档在其所在子集中的位置并取倒数作为其权重(分数)。
下面是RRF算法的python实现:
from langchain.load import dumps, loads
def reciprocal_rank_fusion(results: list[list], k=60):
""" Reciprocal_rank_fusion that takes multiple lists of ranked documents
and an optional parameter k used in the RRF formula """
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results下面我们来创建一个完整的chain,它由generate_queries ,retriever.map() ,reciprocal_rank_fusion三部分组成,其中generate_queries会生成4个多角度的query, retriever.map()的作用是根据generate_queries的结果映射出4个retriever(可以理解为同时复制出4个retriever)与中generate_queries会生成4个query对应,并为每个query检索出来的一组相关文档集(默认为4个相关文档),那么4个query总共可以生成16个相关文档。这16个相关文档集最后会经过RRF算法从新排序后输出最终的4个相关度最高的文档:
original_query = "气候变化的影响"
chain = generate_queries | retriever.map() | reciprocal_rank_fusion
chain.invoke({"original_query": original_query})
这里我们看到了经过最终的RRF算法进行重拍以后的4个最相关的文档,并且从高倒低罗列出了每个相关文档的得分,下面我们来分析一下这些分数是如何统计出来的,为此我们需要提取那些在执行RRF算法之前的结果:
chain1 = generate_queries | retriever.map()
chain1_result = chain1.invoke({"original_query": original_query})
chain1_result 
下面我们可以根据RRF算法在论文中的定义,手动来计算上面这些相关文档的分数:
#气候变化和经济影响。0.16344044051606188
score0 = 1/60+1/61+1/62+1/60+1/61+1/62+1/63+1/60+1/61+1/62
#气候变化引起的公共卫生问题。0.049189141547682
score1 = 1/60+1/61+1/62
#气候变化及其对生物多样性的影响。0.16344044051606188
score2 = 1/63+1/63
# 气候变化如何影响日常天气。0.015873015873015872
score3 = 1/63
print(score0)
print(score1)
print(score2)
print(score3)
这里我们看到我们手动计算的分数与RRF的python算法计算的分数是一致的。
下面我们可以在LangSmith平台中查看最终chain的执行过程中的中间结果,如下图的左侧为最终chain的所有组件如:ChatPromptTemplate,ChatOpenAI,Retriever(4个),reciprocal_rank_fusion,下图的右侧为每个组件所对应的输入和输出的内容:
下图为ChatPromptTemplate组件对应的输入和输出结果:

下图为ChatOpenAI(LLM)组件对应的输入和输出结果:
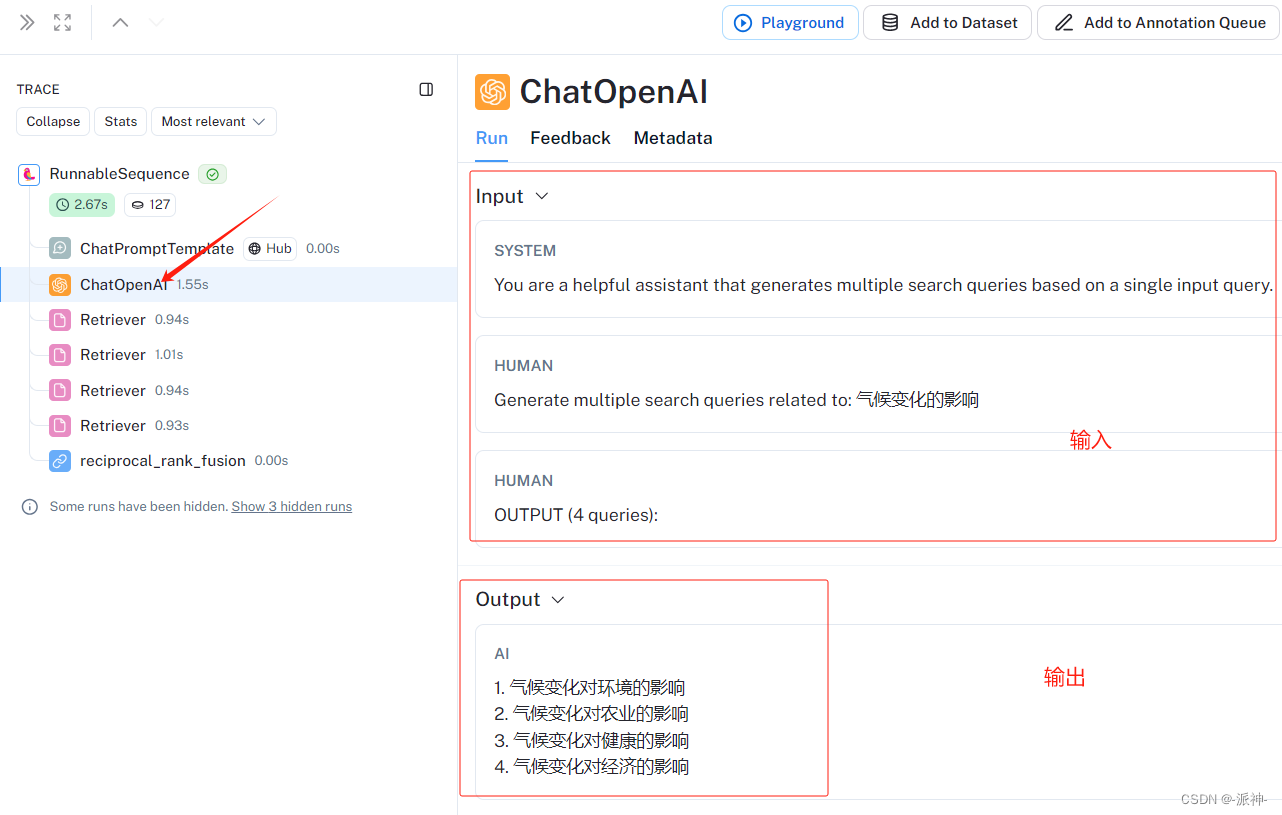
下图为第一个Retriever的输入和输出结果:
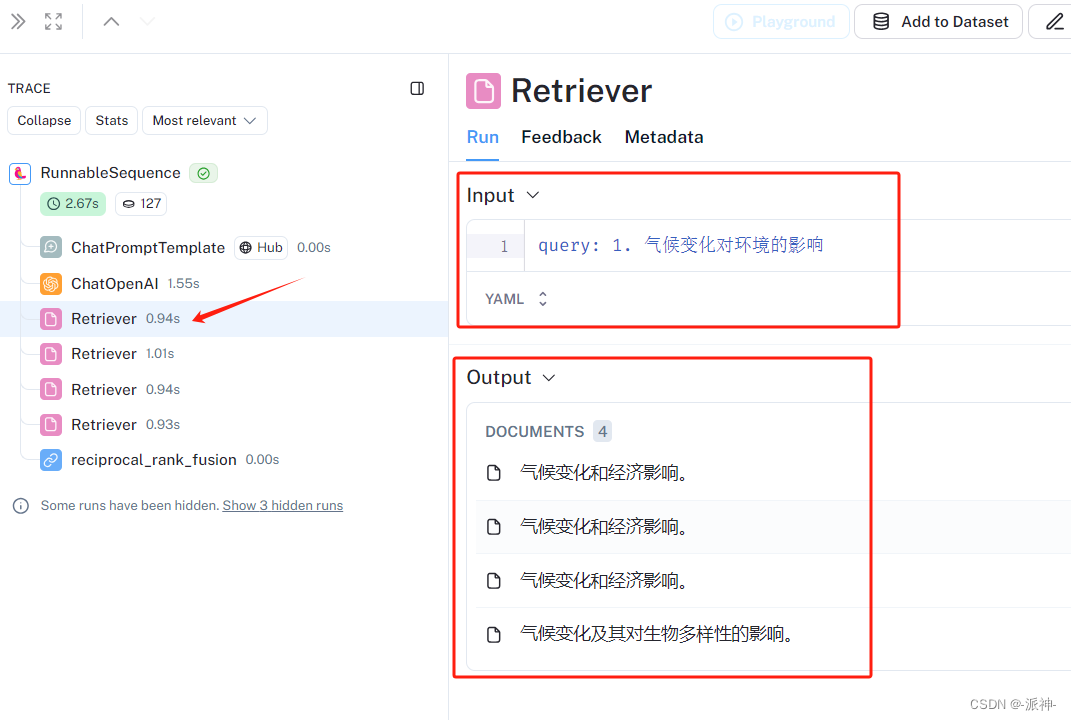
下图为最后一个Retriever的输入和输出结果:
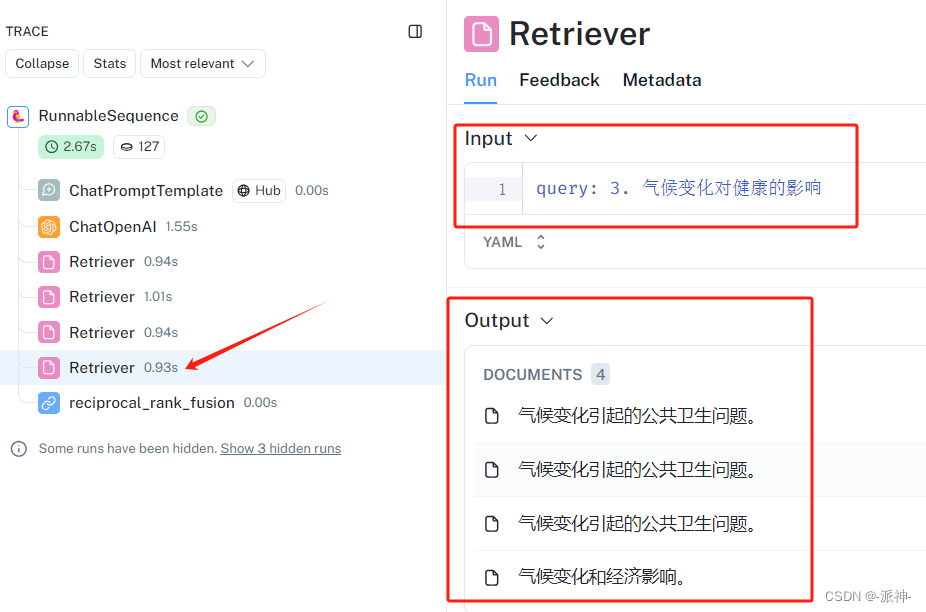
下图为RRF算法的输入和输出结果:
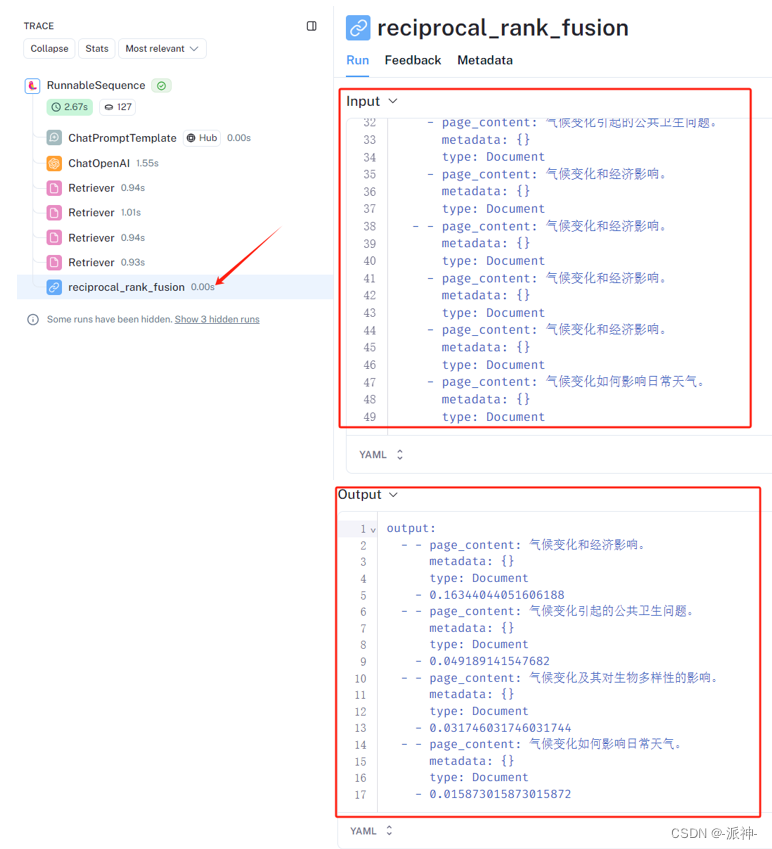
未完待续。。。。